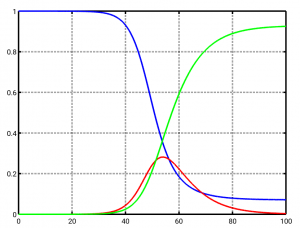
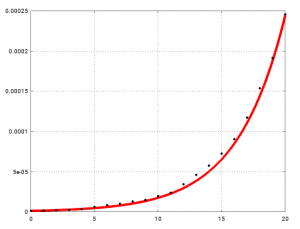
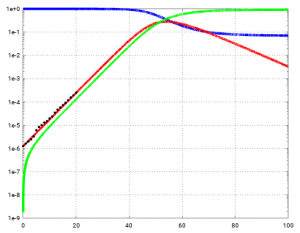
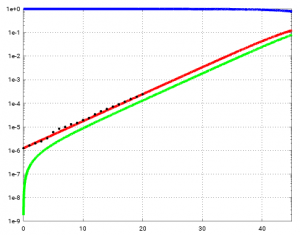
Zusammenstellung von Parametern von SARS-CoV-2 (Achtung, diese Parameter sind keine Naturkonstanten):
Serial interval/Serielles Interval: ca. 4 Tage (z.B. hier aus chinesischen Daten);
Das RKI nimmt zur Berechnung von R0 eine Generationenzeit von 4 Tagen an.
Als „Serielles Interval“ wird die Zeit zwischen Symptombeginn bei Person A und Symptombeginn bei einer angesteckten Person B bezeichnet. Als Generationenzeit die Zeit zwischen der Infektion von A und der Infektion von B. Diese beide Zahlen werden ähnlich oder fast gleich sein.
Basisreproduktionszahl R0: Laut RKI zwischen 2,4 und 3,3
Rückwärtsschau zum zeitlichen Verlauf von R von Anfang März bis Anfang April 2020 in Deutschland (Berechnungen RKI, die angenommene Generationenzeit ist 4 Tage). Hier die Antwort des RKI zur einer oft gestellten Frage.
Inkubationszeit: im Median 5-6 Tage bei starker Spreizung
- Letalität: Laut RKI am 25.4.2020 in Deutschland 3,6 Prozent. Weitere Zahlen hat das RKI hier zusammengestellt. Die tatsächliche Letalität ist aufgrund der Dunkelziffer schwer zu bestimmen. Sie ist zudem stark altersabhängig.
Frühe chinesische Zahlen lauteten (finde auf die Schnelle nur diese Sekundärquelle): - 10-19 Jahre: 0,2 Prozent
- 20-29 Jahre: 0,2 Prozent
- 30-39 Jahre: 0,2 Prozent
- 40-49 Jahre: 0,4 Prozent
- 50-50 Jahre: 1,3 Prozent
- 60-69 Jahre: 3,6 Prozent
- 70-79 Jahre: 8 Prozent
- 80 Jahre: 14,8 Prozent
Bemerkung: Es gibt bisher wenig Daten zu Situationen ohne Dunkelziffer. Auf einem Flugzeugträger wurde die gesamte Besatzung von 4800 Besatzungsmitgliedern getestet und 580 Tests fielen positiv auf SARS-CoV-2 aus. Ein Besatzungsmitglied ist inzwischen an Covid-19 gestorben.